
Supported for CLOUD Deployments + on-premise DEPLOYMENTS + Hybrid Deployments
Overview
Eleveo offers a Speech Recognition package that is installed on a separate, dedicated, server. The solution is provided for both on-premise and cloud deployments. Feature availability may vary based on your installation.
The Eleveo solution does not support multiple engines in parallel. Multiple language packs can be configured (based on what is supported by the given speech engine) but only a single speech engine can be configured.
Speech Recognition
Speech Recognition works with a limited number of languages. Speech Recognition is installed as an add-on to Quality Management and must be configured. This feature provides transcription services for all supported languages. The audio files generated in the contact center or back-office are sent via a dedicated API to a secondary system that processes the recording, analyzes the audio, detects emotion/sentiment, transcribes the audio, and tags the relevant section. View the transcription within the Conversation Explorer.
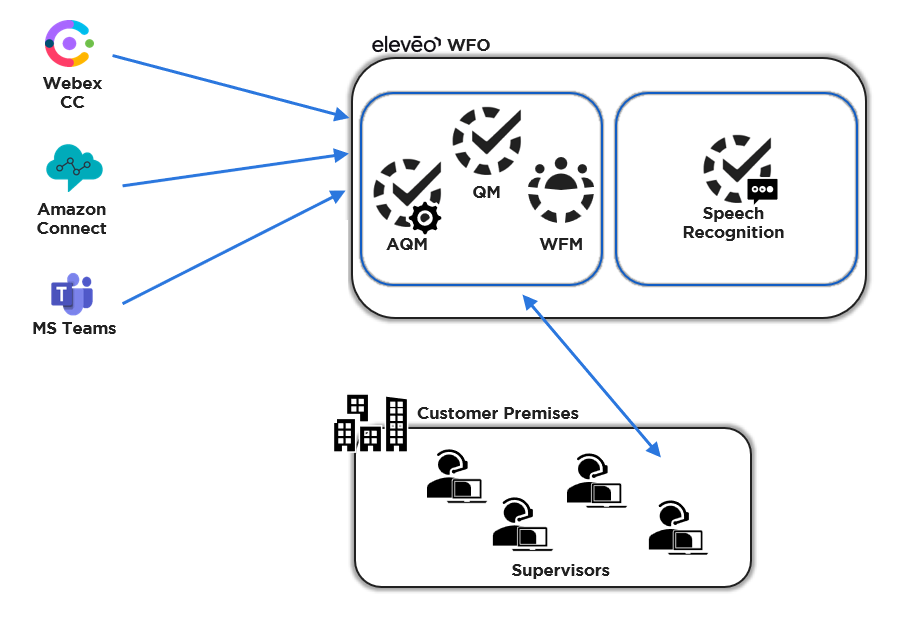
What is Supported - Based on Speech Recognition Service
Languages
|
Speech Recognition - Voci |
Speech Recognition - Phonexia |
|||
|---|---|---|---|---|
|
Supported Languages |
Dialects supported |
Supported Languages |
||
|
|
|
CPU Based Languages |
GPU Based Languages |
|
|
English |
|
Arabic (Gulf)
|
Afrikaans
|
Latvian
|
|
French |
|
|||
|
Spanish |
|
|||
|
German |
|
|||
|
Italian |
|
|||
|
Portuguese |
|
|||
|
Dutch |
|
|||
|
For up-to-date information regarding supported language packs please refer to the providers documentation. |
For up-to-date information regarding supported language packs please refer to the providers documentation. |
|||
|
https://docs.cloud.phonexia.com/docs/products/speech-platform-4 |
||||
Additional Features - Installation Dependent
|
Feature |
Speech Recognition - Voci |
Speech Recognition - Phonexia |
|---|---|---|
|
Transcription |
|
|
|
Phrase Spotting (on top of transcription) |
|
|
|
Emotion/sentiment detection |
Available on transcription utterance as well as participant level |
Emotion is not supported |
|
Acoustic parameters (crosstalk, silence, speed of speech, talk time, gender, etc.) |
|
Gender is not supported Silence and talking count are not supported |
|
Transcription redaction |
|
|
|
Automated language identification |
Automatic recognition for the following language pairs:
|
Language is detected every 30 seconds and then it can start using a different language model.
|
|
Transcription tuning |
|
|
|
Supported formats |
WAV only |
WAV, MP3, MP4 |
|
Availability |
9.1+ Cloud, Hybrid 9.4+ On Prem |
9.4+ On Prem |